
50 Years of Relational Database Theory
Why the relational model is here to stay and why absolutely everyone who ever touched an Excel Sheet can still benefit from knowing its most basic concepts.
2020 marked the 50th anniversary of Edgar F. Codd’s revolutionary paper on Relational Database Theory which introduced many important concepts for handling what is now known as “Big Data” and laid the foundation of Structured Query Language (SQL). Original Paper: “Relational Model of Data for Large Shared Data Data Banks”.
This theory spawned a whole industry focused on efficient and organized access to data, thereby enabling the modern computing age not unlike the advances in personal computing.
A solid foundation
The success of relational databases can be attributed to many mathematical and computational aspects which also facilitated its widespread adoption in the decades following Codd’s publication. Most notable was the relational model’s foundation in mathematical set theory, enabling the relational join which is in essence an intersection of two sets.
However, in this article we want to emphasize the fact that relational database theory is uniquely suited to depict the many business relations in modern enterprises.
Benefits of familiarization with database systems and the relational model
Relational databases are a key foundation of modern business since they are driving all online and many offline commercial activities (at the very least). In contrast to some beliefs, not everyone in the modern workforce can be an IT expert or data scientist. However, we think that everyone should know some basic concepts of modern database theory. From CEOs to accounting clerks, risk managers or sales personnel – everyone can benefit from either gaining a deeper understanding of modern IT architecture and therefore the company itself or simply creating better working documents such as relational excel tables (and YES – there is such a thing)!
For this purpose, we will illustrate a couple of high-level database concepts with a focus on the relational model’s most essential rules:
The purpose of databases
A database does not necessarily have to be integrated into a complex Database System, which also includes Database Management Systems (DBMS), Database Applications, and last but not least the Users. These components make up the skeleton of all modern Database Systems:
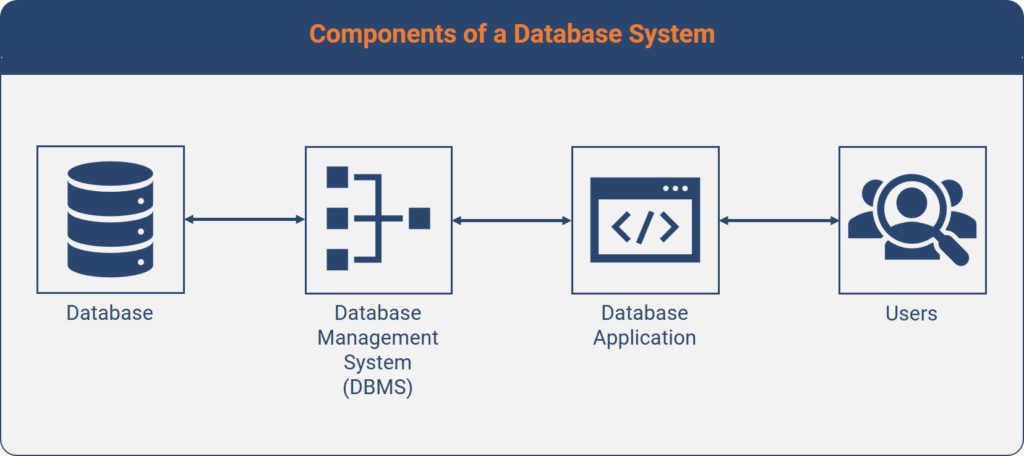
- Database – Stores the actual data in relational tables.
- Database Management System (DBMS) – Acts as a gatekeeper to restrict users or programs from gaining direct access to the Database. All information must travel through DBMS to ensure data quality.
- Database Application – For instance, a website with an online store.
- Users – Generally People. However, a User does not necessarily have to be a human being. Other Programs can be users as well.
On the one hand, a database itself has three primary functions:
- To store data
- To provide an organizational structure for data
- To provide a mechanism for querying, creating, modifying, and deleting data
These are the four primary database operations. A concept which is also widely known as C.R.U.D. (CREATE, READ, UPDATE, DELETE).
On the other hand, a database can store this information together with relationships that are more complicated than a simple list. But what is a relation?
Business is all about relations…
As previously hinted at, in business there are many natural hierarchical relationships among data. For example:
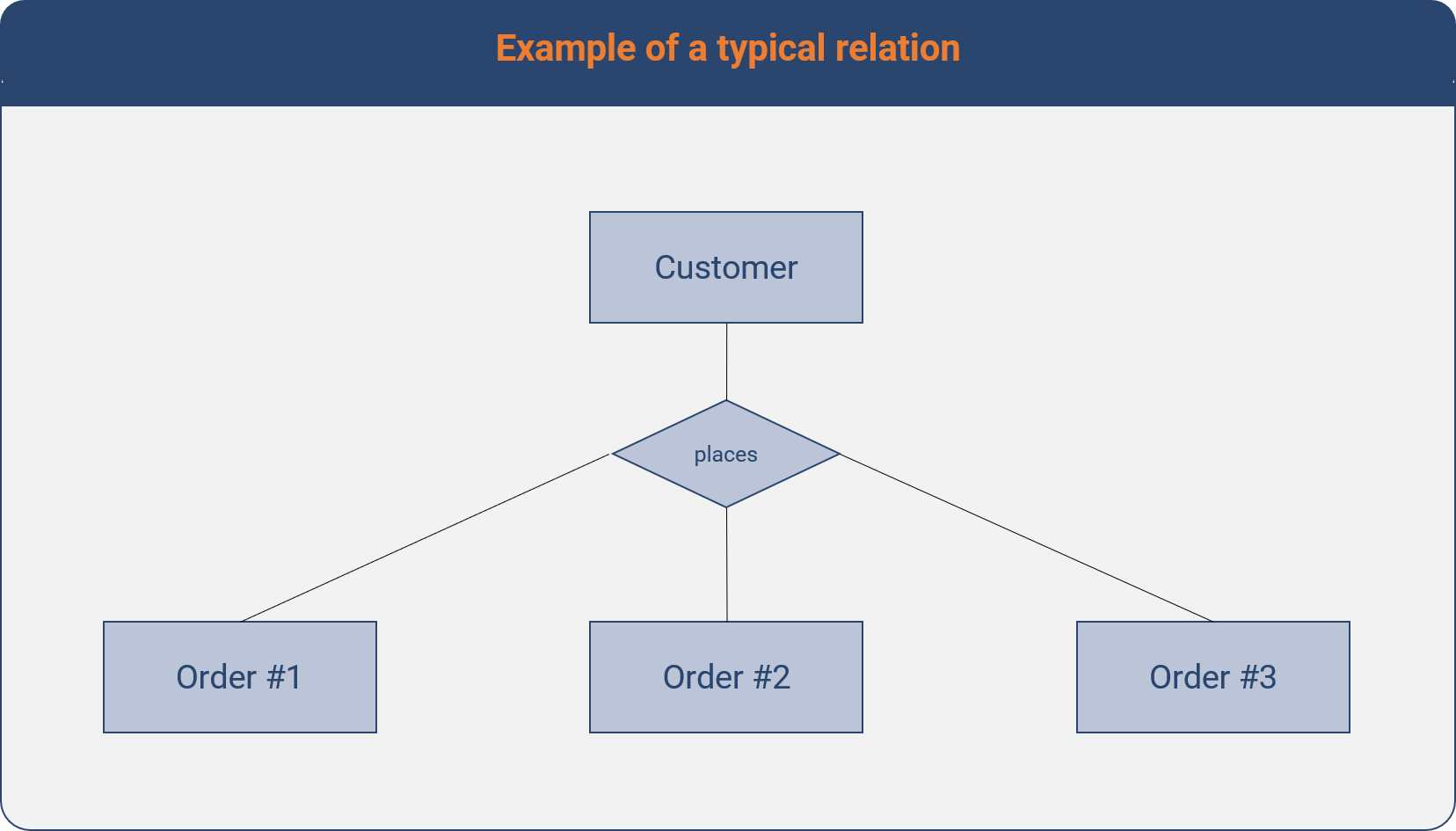
- A customer can place many orders.
- Or put another way: Many different orders can be associated with the same customer
A relational database enables us to model and represent these relationships.
Information complexities and resulting data anomalies
Relations are being depicted in relational tables. These follow a specific set of rules which allows them to avoid certain problems arising from information complexities in contrast to traditional tables or data lists. These are notorious for getting messy and introducing various data integrity problems along the way. However, first we need to define some of these concepts, work out these problems and then introduce the solution in form of relational thinking:
The traditional data list
A list is a simple two-dimensional table which stores data that is important to us for some reason. Let us take a list of projects as an example:
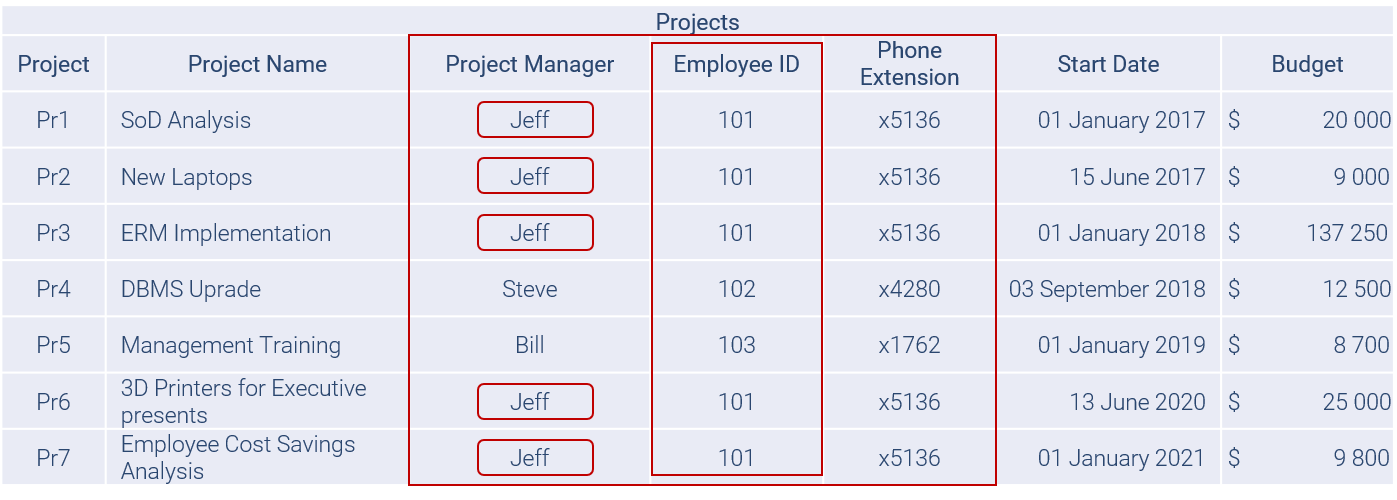
At first glance, this data list might not look all that bad. The table already follows one very important concept:
- Each data field consists of only one value – a name, number, or date, etc. Don’t laugh, this is not always the case out there! [This concept is also known as normal form 1 in relational database theory.]
A negative example would be:

The fields (or cells) above are not atomic. They consist of multiple values – names and numbers mixed. With such a table, almost no further operations are possible.
Problem #1: List Redundancy
However, each row in our Projects table is intended to be self-contained. As a result, the same information may be entered several times. This redundancy might not be a problem on its own, except that we are using more space than is necessary with this approach:
If a particular person is currently managing 10 or 100 Projects, all his associated information would appear in this list 10 or even 100 times! Scaled to the needs of a big corporation this approach would be very wasteful.
Problem #2: Multiple business concepts cause list anomalies
Additionally, in a list each row may contain information on more than one theme or rather business concept. As a result, certain information may appear in the list only if information about other business concepts is also present.
In our list of projects, there is obviously certain project-related data, such as “project name”, “start date” and “budget”. However, in the centre of the table we find various information associated with the project managers themselves – a second concept.
In a relational table none of the manager’s information would be present, except for the data that fully identifies the Manager – ideally the Employee ID, which is only one column in our case.
Resulting list modification issues
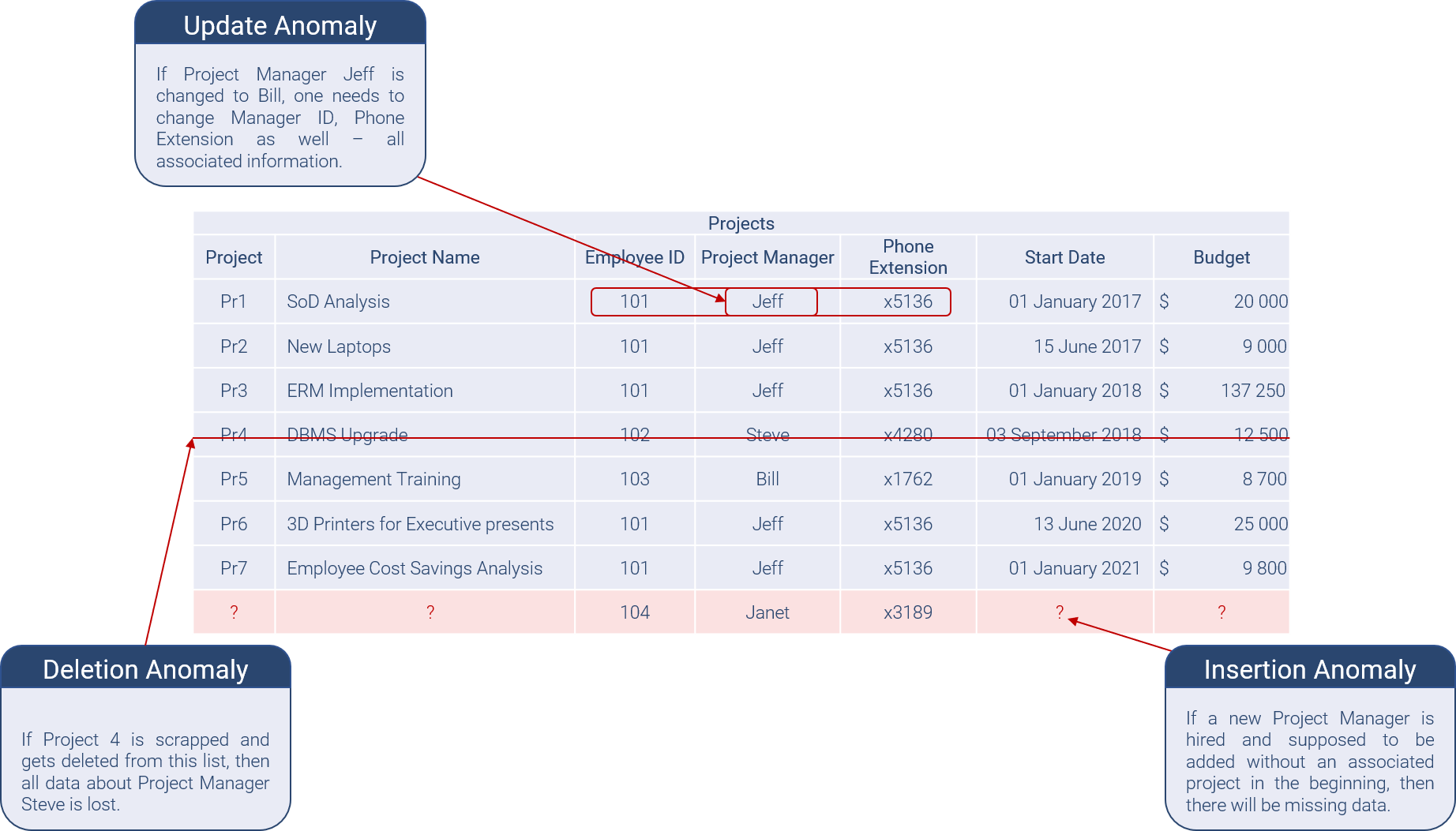
Aside from redundancy, there are typically three major problems or anomalies which get introduced with lists that are mixing multiple business concepts:
- Deletion anomalies
- Update anomalies
- Insertion anomalies
The following illustration explains these anomalies with our easy example. However, we can already see that this data list is a complete and utter mess:
The benefits of relational thinking
Relational databases both solve the problems that are associated with lists as well as enable us to model these natural business relationships effectively!
A relational database also stores information in tables. However, each informational theme or business concept is stored in its own table – a relational table!
Going back to our easy example, a relational approach will break the data list into several parts until each part only represents one business concept – The Projects and the Project Managers. If our company is not only tracking internal projects, but also external projects, then another “customer” table would be needed and put in relation with our projects table – you can now see the general idea. [After separating the business concepts, the remaining tables fulfil all requirements for normal form 2.]
Relational tables or Excel on steroids
As mentioned earlier a relational table also follows certain rules:
- Each column in a relational table represents a specific attribute of an entity.
- Each row represents an instance of an entity.
Our new and improved project managers’ table follows these simple rules:
The Project Manager is our entity which can have various instances – the individual manager. We also defined the following attributes in accordance with our prior example: Manager ID, Manager Name and Phone Number.

Furthermore, the table above has one column which uniquely identifies any record (or row) of data inside – and it is not the name. Given a large enough size of the company, a name could exist multiple times. Therefore, we used an Employee ID column. This column is called the primary key and will later help us to establish a relationship to another table.
Please note, that introducing such identification columns is not always needed. Keys can also consist of a group of attributes, where the combination may act as a key. However, in our case even the combination of a First Name and a Last Name would not be sufficient to uniquely identify a manager. Therefore, another attribute would have been needed. In such cases, it is easier to introduce a new primary key.
Putting the pieces back together
Our data list is now broken apart into several tables, but these need to be linked or joined somehow. In relational database theory, these relations are modelled by linking relational tables together using matched pairs of values. These matching pairs of values are the keys from before.
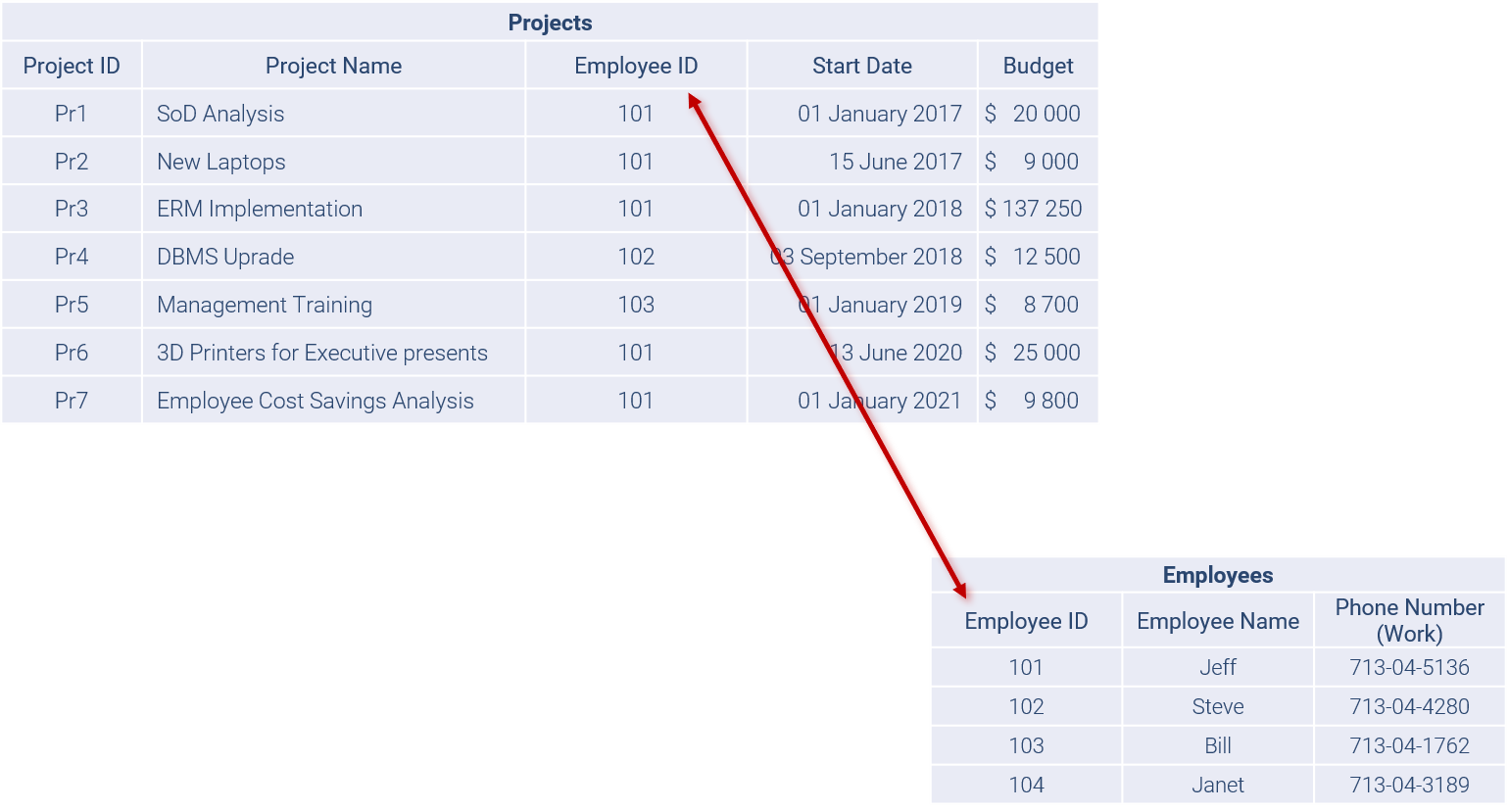
Ideally, we would also like to create a separate table for all phone numbers that are stored, and which relate to the manager, in case the company also tracks multiple numbers such as Home, Work, Mobile.
At first glance this approach towards tables and databases sounds like more work. Indeed, it is more complicated than a simple list. However, it also offers many advantages when working with data, such as minimizing data redundancy, preserving complex relationships among different topics, and it allows for partial data (so called null values).
SQL, NoSQL – There is more to it
In relational database systems these tables and their relations are processed via SQL (Structured Query Language). As mentioned before, you can create new tables or entries, read, update, or delete them.
This is where the mathematical foundation becomes important. SQL also allows us to interact with multiple tables by essentially using mathematical set operations like unions which we all still know from school 😉
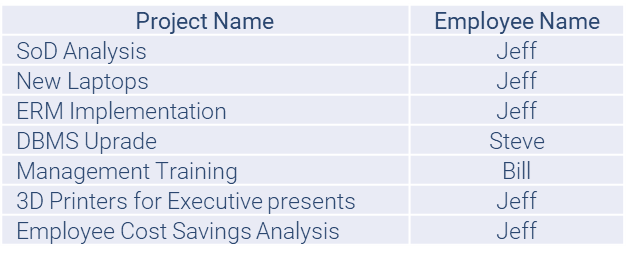
Let’s assume we want to view the project names together with the manager names. Since we employed our matching pairs of values, we could quickly query such a view:
SELECT Projects.ProjectName,
Employees.EmployeeName,
FROM Projects, Employees
WHERE Projects.EmployeeID = Employees.EmployeeID
(Please note that the naming convention we employed so far is not usable for actual relational tables and SQL. For this code snippet, we used the familiar attribute names simply without spaces.)
Most modern Database systems are relational (RDBMS) and can therefore be accessed via SQL. However, the last decade also brought several NoSQL database systems, such as MongoDB, which are document-based.
Obviously, we only touched the surface in this article. So far, we introduced two fundamental concepts (normal forms). For an efficient database system, one should employ at least two more. However, these are the ones I try to follow even when I am creating quick tables in Excel or other working documents.
How to use these concepts even within Excel
Assuming you have different tables in Excel for each business concept, how would you establish the relations there? Well, nowadays Excel actually offers a couple ways to employ relational practices:
- The oldschool method: Using VLOOKUP to combine data from multiple tables to create a PivotTable. (works for all Excel Versions)
- The modern solution: Excel 2013 and newer versions come with an Excel data model which you can use with Pivot tables to analyse multiple tables. Here you can find a small tutorial.
- For more complicated analyses, there is a new Power Pivot Add-in which allows you to work with larger datasets among other benefits. Note: You will have to activate it first.
For people interested in general Database lessons including their structure, the relational model, Database Design and SQL, I can recommend Dr. Daniel Soper’s short series on Youtube.
If you are interested in other topics related to Risk Management, Internal Controls or IT System scoping, be sure to check out the following articles:
Tag:CRUD, Database Systems, Relational Model, SQL